Introduction
This small project implements a fully connected neural network using only matrix operations, a logistic activation function, and manually derived gradients. There is no high-level frameworks like keras or torch, just linear algebra and backpropagation written explicitly.
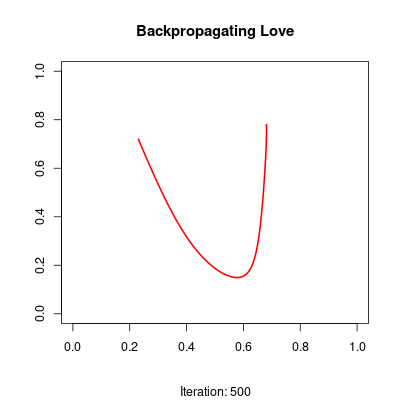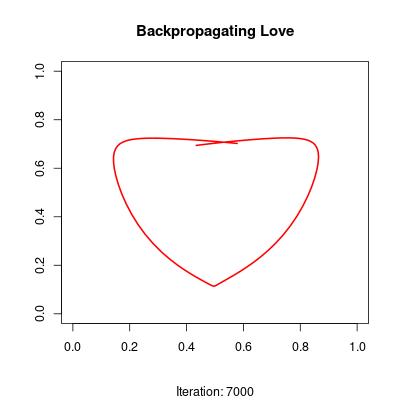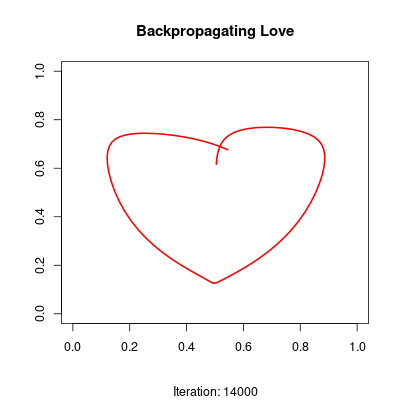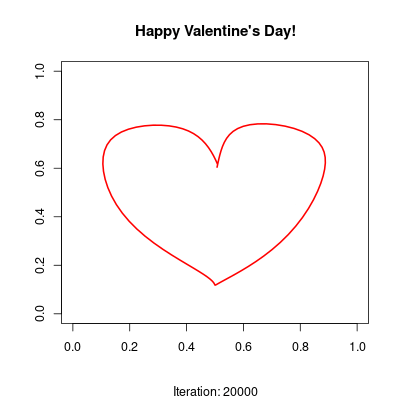
The network is trained to approximate a parametric heart curve. During training, frames are saved and combined into a video, so you can watch the model gradually learn the shape.
Network Architecture
This network is a Multilayer Perceptron (MLP) structured as a \(1 \to 6 \to 7 \to 2\) feed-forward architecture. It maps a single input scalar representing progress along a path through two hidden layers of 6 and 7 neurons to a 2D coordinate output.
Input Layer (\(L_0\)): A single node (\(n=1\)) representing the value \(x\), the amount traveled along the curve from 0 to 1.
Hidden Layer 1 (\(L_1\)): Six neurons using the logistic sigmoid activation function \(\sigma(z) = \frac{1}{1 + \exp(-z)}\) to capture initial non-linear features.
Hidden Layer 2 (\(L_2\)): Seven neurons that further process the signals to handle the complex geometric “lobes” of the heart curve.
Output Layer (\(L_3\)): Two nodes representing the \(x\) and \(y\) (or \(y_1, y_2\)) coordinates of the curve’s position in 2D space.
Connectivity: The topology is fully connected, meaning every neuron in one layer is linked to every neuron in the next via a weight matrix (\(W\)) and a bias vector (\(b\)).


Gradient Descent Process
For each iteration of the training loop, the network updates its parameters to minimize the distance between the predicted coordinates (\(a^{(3)}\)) and the target heart curve coordinates (\(y\)).
1. Cost Gradient Calculation:
The error is propagated backward through the layers. For the final weight matrix (\(W^{(3)}\)), the Jacobian is calculated as:
\[\mathbf{J}_{\mathbf{W}^{(3)}} = \frac{1}{N} \sum 2(\mathbf{a}^{(3)} - \mathbf{y}) \cdot \sigma'({z}^{(3)}) \cdot \mathbf{a}^{(2)T}\]
2. Stochastic Update:
The code applies “aggression” (learning rate) and optional “noise” to prevent the model from getting stuck in local minima:
\[\mathbf{W}_{new} = \mathbf{W}_{old} - (\mathbf{J} \times (1 + \text{random\_noise})) \times \text{aggression}\]
3. Topological Impact:
\(W^{(1)}\) (6x1): Adjusts how the single input \(x\) is mapped to the 6 neurons of the first hidden layer.
\(W^{(2)}\) (7x6): Adjusts the 42 unique connections between the first and second hidden layers.
\(W^{(3)}\) (2x7): Adjusts how the 7 high-level features are combined into the final \(x\) and \(y\) coordinates of the heart.
The script performs approximately 20,000 of these updates to refine the curve. Each iteration slightly shifts the 2D coordinates produced by the output layer until they trace the distinctive heart shape defined in the training_data function.
Acknowledgments
This project is based on one of the lab exercises from Imperial College London’s “Multivariate Calculus for Machine Learning” course. I re-implemented the network in base R, translated the mathematical components from Python, and extended the project with visualization pipeline to produce a frame-by-frame learning animation.
Source Code
Source code is available on GitHub: Backpropagating Love.
See Also
Here are some related posts that you might find interesting:
| Title | Reading Time | |
|---|---|---|

|
Animation of Spatial Data | 7 min |

|
Nerdy Valentine’s in Python, R, and Matlab | 4 min |